
Usually an honor's thesis in my previous department involved researching something, and the thesis was the result; in my case, however, I considered the work itself the result, and the thesis a formality to explain to my supervisors what I'd done.
Note that I used CommunityWiki to make the text into HTML, so there are some hyperlinks below that point to CommunityWiki; the actual thesis did not have hyperlinks (just some manually written U.R.L.s in the text).
-- bayle
This project is an exploration of a new collaborative technology, "wiki". This technology was applied to create three separate discussion tools for researchers in the fields of neuroscience, artificial intelligence, and brain imaging. A substantial amount of content was written for two of these tools in order to create a new information resource for the respective research communities.
In addition, a new idea was developed and implemented which attempts to apply lessons learned about collaboration from wiki communities to the domain of software development. The result may ultimately be an exciting new way to develop software.
I wish to thank my advisors, John Gabrieli and Jan Borchers, for their advice and support on this project. I thank David Andel for his collaboration on NeuroWiki and AIWiki, for hosting both projects on his server, for starting AIWiki, and for many interesting discussions. Finally, I thank all the participants of MeatballWiki for their excellent analyses of so many topics in the sociology and technology of collaboration, and for providing many interesting discussions.
Wikis are a new form of collaborative website invented by Ward Cunningham in 1995 [1]. The basic idea is that any user has the ability to edit the content of the website. In order to understand the basic idea, consider the metaphors behind different sorts of websites.
A classical web page is based on the metaphor of a newspaper. One organization publishes the webpage, perhaps after soliciting contributions. Then, many readers read the webpage.
A discussion board is based on the metaphor of a cork board with pushpins. Each message is written on its own piece of paper. Each person writes messages and posts them onto the board.
A wiki website is based on the metaphor of a communal whiteboard with a marker and an eraser. Every person both reads what is written and modifies the contents of the board.
Wikis do, however, have one advantage over a physical whiteboard. Wikis automatically remember some of the past history of the board. This means that if a vandal should come along and erase part of the board, another user can simply restore the previous version.
Wikis are composed of many web pages, each of which acts as a single whiteboard with a memory. They also provide mechanisms for hyperlinking and indexing the pages. They also have a feature that provides a summary of all recent modifications to the wiki, allowing you to keep abreast of new and modified text.
Discussion boards are frequently used for electronic conversations. Wikis can be used for conversation, but they also lend themselves to something that discussion boards do not; collaborative writing and editing of documents. For example, one person can write a paragraph on a web page, and then another person can revise the first paragraph and then add a second one. This allows wikis to be not only mediums of discussion, but also collaborative knowledge repositories. Actual wikis have run the gamut from places of discussion (e.g. [2]) to collaborative encyclopaedias (e.g. [3]), while most occupy an interesting middle ground (e.g. [4], [5]).
Wikis are also good at providing a collaborative organization system for small projects, with collaboratively written and maintained to-do lists, milestone descriptions, discussions, and project reports ([6], [7], [8]). It should be noted that although by default most wikis allow any user to edit any of the content, many wikis do provide access-restriction capabilities if desired; both read-access and edit-access can be restricted.
The radical decentralization of power in wikis is surprising to many, and there has been much analysis as to why it can work (for example, [9], [10], [11]). There are also many theories about the effect of this control structure on a wiki community and on the communal decision-making process. Since there has been much good work on the topic of the social conventions and organizational structures found in wikis, I won't attempt to repeat it all here. Although there is disagreement, one of the most popular views has been concisely summarized by Clifford Adams: "...most Wikis replace technical security with social and political limits." [12]
In other words, while the wiki software will let anyone do anything to the content, the user community enforces norms of quality and style. The situation is much the same as the legal system in the real world. There is nothing in the laws of physics to stop you from stealing from or killing another human. However, the social community prevents you from doing so. The flexibility of wiki software does not mean that anything goes; in fact, some wikis enforce perhaps overly strict restrictions in the style and type of content allowed. The editorial policy for a given wiki site is not hardcoded into software, but rather is imposed and implemented by humans.
Message boards, (newsgroups or web-based) and email lists are the most widely used forms of electronic discussion. However, both of these suffer from a set of problems.
First, similar conversations are often repeated over and over every few months or years [13].
Wikis have much less of a problem with this, as the knowledge gained from old conversations is kept on the wiki itself, rather than buried in the message archives. In the course of making a comment on a wiki, one often finds that a similar comment has already been made (and responded to), saving everyone time.
Second, on a message board or email list, there is often a large amount of redundancy. Many messages will say the same thing as other messages. After redundancy is discovered, there is nothing to be done about it; what is said has been said, and goes into the archives. Someone looking for information on the topic later will be faced with multiple messages to read through instead of just one.
On a wiki, by contrast, everything can be modified. If two comments repeat each other, one of the comments can simply be deleted.
Third, on a message board or email list, most messages are essentially "first drafts". Many messages lack clarity, and readers are forced to wade through a large number of confusing messages. However, on a wiki, confusing text can be revised later, by the original author or by others. Since text on a wiki is effectively "edited" a number of times by a number of people, the end result is greater clarity.
Fourth, the organization on a message board or email list is necessarily based on the "threads" of messages. Knowledge is generally organized according to date. This can make it hard to find information in the message archives later [14].
A wiki provides much more opportunity for structuring information. Information can organized by topic onto different web pages, and tables of contents, categories, or indices may be created and dynamically updated by the user community. Furthermore, information may be reorganized long after it is posted. Successful wikis can become better and better organized over time, in contrast to email lists and discussion boards, which start out with a minimal level of structure and stay that way.
Many of these problems could be solved by having contributors submit information to a webmaster (or group of website administrators), who organizes the information into a structured web site. However, the need to go through a webmaster introduces new problems. First, the webmaster's time is limited; the amount of administration time devoted to maintaining the site must increase proportional to the usage of the site. Often the webmaster's time does not scale with the community and the result is stale content [15]. Second, the webmaster may have goals for the site which conflict with or do not encompass the goals of the wider community, leading to a proliferation of websites with similar focus. Wikis do not require content to go through a webmaster bottleneck.
Finally, if the goal is to create a collaborative document, such as a jointly written tutorial or academic paper, a wiki is a better fit as the data model (text which is modifiable by different people) is more suited to the goal than, say, email (whose data model is a collection of separate texts with different authors).
The wiki concept has already been successfully exploited to build a number of successful websites. Here are three examples.
The largest wiki is the English-language encyclopaedia called WikiPedia (http://www.wikipedia.org). The WikiPedia community, which is now over 1,000 people, have written over 120,000 community-edited encyclopaedia entries, of very good quality and consistency. This is impressive, especially considering that WikiPedia has only been around for two and a half years.
My favorite wiki is MeatballWiki (http://www.usemod.com/cgi-bin/mb.pl?MeatballWiki). MeatballWiki is about online communities, culture, and communication. MeatballWiki has over 2,000 pages and over 100 contributors. Most pages on MeatBall start out with a few paragraphs of collaboratively written text expressing a thesis or idea, and then continue with a discussion composed of individual comments. MeatballWiki contains a lot of well-thought out analysis of the sociology and methodology of different systems of collaboration.
The original wiki is named WikiWiki (http://c2.com/cgi-bin/wiki?WelcomeVisitors). WikiWiki was created in 1995 to discuss topics in programming, especially the idea of pattern languages as applied to program design. WikiWiki now has over 24,000 pages and over 1,500 users.
The first subprojects are the creation of a public wiki web forum for neuroscience and for artificial intelligence. The sites are called NeuroWiki (http://purl.net/net/neurowiki) and AIWiki (http://purl.net/net/AIWiki) respectively.
Ultimately the goals are to create two interdisciplinary communities which both tracks current research and ideas (much like a "Current Opinions in ..." journal), and also provide a platform for active collaboration and discussion. It is hoped that the sites will eventually serve as a reference point for people in academia who want to catch up on the latest trends in areas outside their subspecialty. For example, a specialist in hippocampal cellular biology may want to know what memory-related advances have been made in cognitive neuroscience in the last year or two. In A.I., a machine learning specialist may want to know what the state of the art is in planning.
Together, the two sites aspire to cover much of SymSys. NeuroWiki is concerned with anything that has to do with minds which are embodied in brains. NeuroWiki topics range from the philosophy of mind to psychology to computational modeling to neurobiology. AIWiki is about artificial minds.
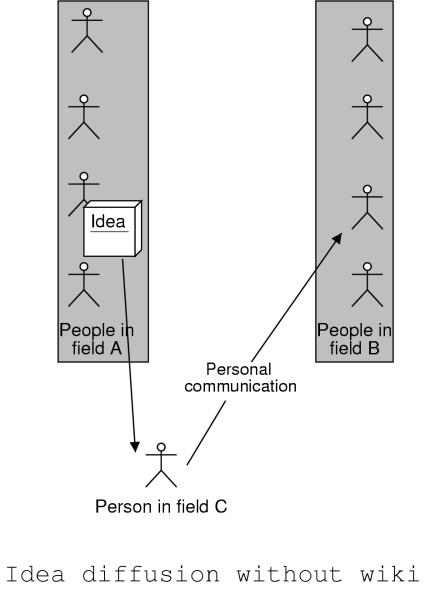
The advantages of wiki will be particularly useful for diverse, fast-moving, interdisciplinary fields such as those in cognitive science. One problem in such a field is disconnection between various subcommunities. It takes time for relevant information to diffuse across disciplinary boundaries; this time will be reduced with a wiki.
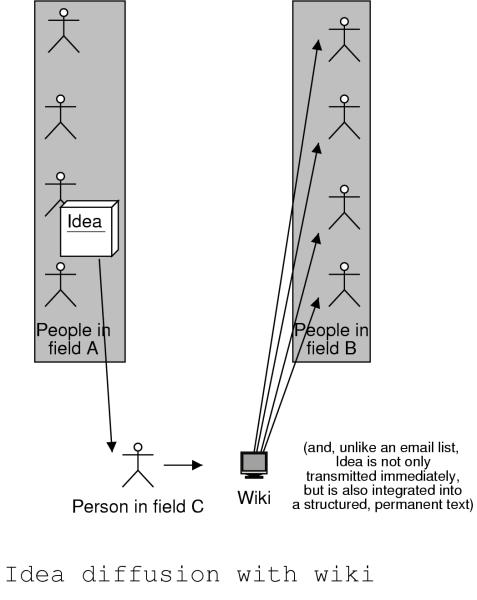
For example, if a researcher in subfield C notices that a discovery in subfield A would benefit subfield B, often their only outlet would be to tell a friend in subfield B. With NeuroWiki, however, the researcher can post a link to the information on a web page in NeuroWiki concerned with subfield B. This is more efficient than telling a friend because now lots of people in subfield B will receive the pointer, rather than just one. In addition, this method is better than posting the information to an email list, because with a wiki the pointer becomes a part of a evolving, highly structured text, rather than an ephemeral utterance which disappears in a week.
There are already ways in which recent progress in various subfields in chronicled. However, these usually take the form of summary articles written by individual researchers every couple of years [16]. There are three ways in which wikis can do better. First, wiki summaries are less likely to be confined to a single point of view on recent research, because other points of view can be added by others at any time [17]. Second, wiki summaries can be continually updated, whereas conventional summaries only come out at lengthly intervals. Third, there is little danger in a wiki of the summary writer overlooking an important piece of research; such omissions would most usually be corrected on a wiki because someone else would add the missing piece. All three of these advantages spring from the ability of wikis to harvest the labor of a large number of people to asynchronously improve each article.
As wikis are not just discussion spaces but also knowledge repositories, the creation of a new wiki involves creating and organizing a critical mass of initial content [18]. This is conventionally called "SeedPosting". Hence, the creation of NeuroWiki and AIWiki involved mainly the creation of this content.
[the rest of this section tried to approximate how many typewritten pages worth of content I'd written for NeuroWiki and AIWiki. I think this is sort of silly beancounting, but necessary for demonstrating how much time I'd put into the honor's project. So I took it out of this public version; lemme know if you're interested and I'll send it to you. References to footnotes [19] and [20] were in this deleted section.]
These web sites will not be shut down at the end of this project; they are expected to continue to grow until they become valuable resources to their target research communities. The ultimate measure of success will be the ability of the sites to attract a community once they are advertised to the public. This will be judged by the number and prestige of the people who write content on the sites.
It is not clear what the best strategy is to advertise these sites to the relevant academic communities. Researchers tend to be busy and (ironically) not to have much time to look at new ways of doing things. The sites ultimately will serve both as collaboratively written reference works and as hubs for discussion. However, the sites can do neither of these well until there is an initial base of contributors. So there is a familiar chicken-or-the-egg problem.
One strategy is to advertise the sites on community mailing lists. The advantage is that the people on the mailing lists are exactly the target audience/authors for the sites. The disadvantage is that the people may take a quick look at the sites, see that there is not enough content, and write them off. This would be unfortunate, because the real power of the idea lies in the collaborative nature of the sites, rather than in the initial content. By contrast, when a person experienced in wikis visits a wiki site which does not have as much content as they would like, that person will often react to the problem by adding more content. Another strategy is to advertise the sites on public web sites concerning the subject and on usenet groups. The advantage is that the sites will reach a wide audience and will remain linked to from many pages. The disadvantage is that visitors will be attracted who are not professional academics. This would be fine, except that later academic visitors may conclude that the site is not intended for a rigorous audience (and shy away).
A third strategy is to give potential users an initial interface that they already know. That is, to solicit entries from scientists in the relevant fields the same (old-fashioned) way that other research encyclopaedias do. The advantage is that people may initially participate without bothering to acquire an understanding of wikis. The disadvantage is that people may shy away from spending their time writing an entry for a project with little prestige.
While initially I tend to prefer the third strategy, I expect that a combination of all three will be needed to grow the community.
In a conventional wiki, there is a piece of software on a webserver which runs the wiki. This software maintains a database of web content. The community of users on the web write and edit the web content.
In a C.P.W. (community programmable wiki), the user community may alter not only the web content, but the actual code of the wiki software which is running the site.
I started with an open-source wiki software application and modified it in order to add functionality, creating a C.P.W. I call my system "CPW" [21]. It is on the web at http://purl.net/net/cpw.
There are a number of reasons that a C.P.W. is desirable.
First, it is always interesting to take concepts to their logical conclusion. The fundamental principal of wiki is that everyone in the user community has equal control over every part of the site. In conventional wikis, however, the webmaster still has exclusive access to the site's underlying software. It will be interesting in itself to explore what happens when the principal of community control is applied more broadly.
Second, many who have analyzed the social dynamics of wikis conclude that, in the context of a wiki collaboration model, powerful individuals are harmful to the community [22][23]. Hence, for the sake of the community, it may be helpful to take the exclusive power of control of the software away from the webmaster and distribute it to the community [24].
Third, often a wiki's host does not have the time to upgrade the software. With a C.P.W., that duty can be distributed to a large number of people rather than sitting on one person's shoulders.
Fourth, the collaborative model of wikis has proved very effective for creating textual content. If the same model works for software development (where the content is computer code rather than human-language text), it could prove to be more efficient than current collaboration models. There is already evidence that greater decentralization is better for software development [25]. It must be noted, however, that software is essentially different from natural human languages. For example, if one page of an English document is changed drastically, the rest of the document will probably still be understandable. However, if even one line of a software program contains an error, the entire program may fail to run [26]. Because of this and other differences, any extrapolation about the suitability of wikis for software development based only upon its performance with textual content is only a guess.
In other words, CPW should enable wikis to become more up-to-date and for newly available wiki features to more quickly be adopted by wiki web sites, while simultaneously decreasing the workload of the site administrator. In the best case, it is also possible that CPW will enable a new collaborative software development paradigm that may accelerate the pace of software development, including the development of software that has nothing to do with wikis.
The idea of a C.P.W. has been suggested by various different wiki users in different places. There are a number of mentions of the concept on the PortlandPatternRepository and on MeatballWiki, under such names as SmartWiki, MetaWiki, SoftWiki, and PublicScript.
Zygo Blaxwell has created a C.P.W. which he calls "SoftWiki". However, the system is currently unavailable to the public. Also, the system is written in Tcl, a programming language less popular than Perl, which I used (and hence, mine may be more inviting to other developers). In addition, my project was based on an already-popular wiki application, which means that it will start out with a large number of standard features. I am not aware of any other C.P.W.s besides SoftWiki and CPW. [27]
LambdaMOO is a collaborative software application similar to the C.P.W. idea in that the user community can modify the software. LambdaMOO has it's own programming language, however, in contrast to CPW which uses a well-known language. In addition, I know of no instances in which a wiki was written inside the LambdaMOO environment, so LamdbaMOO does not currently have wiki functionality.
UseMod is the open source wiki software which CPW is based on. UseMod is a featureful yet simple and easy to use wiki which is fairly popular. CPW was written by starting with UseMod and then modifying it and extending it to provide new features. These new features allow the user community to modify the source code of the software. Both UseMod and CPW itself are released under the GPL open source license.
Any C.P.W. would have to confront the issue of computer security. If arbitrary users can change the software code, then they have some amount of control over the server running the code. They could add code to the software to destroy data on the server, to lock out other users from the system, or to use the server as a proxy to conduct attacks on other systems.
Dealing with this basic security issue was the goal of much of the programming effort that went into creating CPW.
There are three layers of security for CPW.
The first line of defense for CPW is peer review. No change in the code will be executed through CPW until the community has a chance to review the proposed change. Any member of the community can veto any change. Any suspicious or ill-understood change should be vetoed.
Experience with other wiki systems has shown that peer review is an effective security measure [28]. On a conventional wiki, peer review is in fact the only security measure preventing a vandal from corrupting web content. The success of conventional wikis at providing quality content despite frequent attempts at vandalism (MeatballWiki is attacked by vandals more than twice a month, for example) suggests that peer review will be an effective security mechanism in the domain of software code, as well.
The peer review system means that if an attacker wants to enter malicious code into CPW, they will have to find code which is malicious but which looks perfectly innocent to everyone else -- this may be a difficult task.
The second line of defense is the "Safe" extension module of the Perl language.
The "Safe" module allows one run Perl code while disallowing certain operations (such as file access). One can also use the "Safe" module to allow operations only when certain conditions are met.
When CPW is invoked by the web server, all of the user-modifiable code is run under the aegis of the "Safe" module. There is a list of permitted operations (this list itself is NOT user-modifiable). The "Safe" module is instructed to allow the code to execute only operations which are on the list.
The list is designed to allow the code to serve a web page and run the wiki while not giving it the power to do anything malicious:
Unix-like operating systems are designed to be used by multiple users, and have a number of security features to restrict the power of individual users to access parts of the system. In my installation of CPW on a GNU/Linux system, I made full use of these features.
First, CPW is given it's own user account. The CPW user account is barred from accessing any files except those in the directory reserved for CPW.
Second, CPW is run inside a "chroot jail". This means that CPW is run inside a little mini-filesystem in which the most sensitive system files do not even exist. This is another barrier to prevent malicious code in CPW from attacking the server on which it is running.
There are many conceivable ways of allowing members of the user community to modify software code. Three criteria were used to choose one for CPW. The process of modifying CPW's code should:
To satisfy the first criteria, let's look at how a developer would typically contribute to a collaborative open source software project. Assuming the developer is not one of the core developers of the project, a developer might:
The process of submitting a change to CPW mimics this familiar process. In order to contribute an improvement to the CPW source code, a developer would:
In step 3, "post the improvement on the wiki site", the improvement is literally posted onto the site the same way that textual content is. In fact, the improvement appears as text on a normal wiki page, alongside discussion.
In a conventional wiki, when someone makes a change to the text on a web page, any other member of the community can undo this change. This prevents any member from vandalizing or deleting important data. The effect of this is that important changes can only be agreed upon by consensus; each community member effectively has a veto over any changes.
In some wiki systems, this process is made more explicit for certain actions. For example, the UseMod wiki software requires a consensus approval for the community to delete a web page. If a user wishes to delete a page, they put a notice of pending deletion on the page. If the notice is undisputed for two weeks, the page is deleted. But in the meantime, anyone may veto the deletion of the page simply by removing the notice of pending deletion.
The approval process for code in CPW mimics this process. After a code change suggestion is posted, there is a peer review period before the change is actually made to the code. During the review period, any community member may veto the change, or extend the review period.
When the peer review period has expired, presuming the code was not vetoed, the CPW software actually makes the change which was suggested.
This means that any changes to the code are subject to consensus approval by the other community members. This is the same mechanism used to ensure quality content in normal wikis, hence there is reason to believe that it will be sufficient to produce quality code.
Other sources also indicate that peer review greatly improves the quality of code. Code review has long been an important part of software quality control (see also [29]). More recently, studies have shown that the practice of "pair-programming" increases code quality [30] (see also [31]).
Since proposed code changes are literally incorporated into the dialog on the wiki, users can access and organize proposals for changing the code the same way that they manage content on a conventional wiki. Wikis have special mechanisms for generating lists of changed content and for categorizing content, and all of these may be applied to keep track of proposed changes to the code.
In addition to allowing users to re-use familiar tools, one advantage of this approach is that the code being discussed is located near the discussion. Not only is this convenient, but by providing context for the discussion, it provides a hint to participants to keep the discussion confined to the proposal at hand.
In addition to the broad overview given here, I have written technical documentation of the design and usage of CPW. It is available on the CPW site at http://purl.net/net/cpw, or in Appendix E. Note that CPW is in the midst of a name change, and is still referred to as "SPW" in the documentation.
Work on CPW is just beginning; there are many directions that future work could take.
A useful development methodological idea is "unit tests". A unit test is just an automated test of software which is meant to be applied often, so as to reduce the amount of new bugs created as the software is changed. I plan to add unit tests to CPW. Just before the source code is to be changed, the software will automatically run a suite of unit tests (all of which worked before the change). If any of the tests fail, the attempted change will be rejected. This will reduce the chance that a source code modification will break existing functionality.
In addition, unit testing will add to the security of the system. Testing the security features will be part of the unit tests; hence, some kinds of source code modifications which would compromise the security of the system will be automatically blocked.
One standard tool in collaborative software development is CVS. CVS is a versioning system, that is a system which both archives old versions of software and also synchronizes changes when multiple people work on the same code. I plan to add CVS support to CPW. Initially, this will be useful for formalizing the development process, and for keeping track of old versions. Further down the road, my vision for CPW includes user subcommunities branching and merging the code so that subcommunities can explore different development paths simultaineously [32].
Literate programming is an approach that emphasizes documentation the source code of a program to the extent that the program becomes as much a human-readable text as it is "code" for a computer to execute [33]. I feel that CPW could evolve into an ideal tool for developing literate programs, because parts of the program can sit side-by-side with active human discussion. In the future I hope to extend CPW so that not only patches, but all of the source code, appears on web pages within the wiki. I hope to further explore ways to make changing the source code more like posting a comment on the internet.
Currently, due to the need for a 4-day peer review period, there can be no "immediate gratification" when suggesting a change to the code. It would be interesting to explore systems to conquer this limitation. I envision a combination of a web-of-trust system [34] and a more explicit peer review system. The aim would be to allow quicker acceptance of suggested changes while ensuring that each change has been peer reviewed by a number of trusted, high quality reviewers. Communal consensus would ultimately still be needed for any change, however, because any change could be "backed out" by other members of the community later on.
This subproject involved consulting with and setting up a wiki for Professor Gabrieli's lab. The wiki will be used to create an archive of methodological tips for brain imaging researchers.
The first (and, possibly, main) task of the wiki will be to provide informal documentation for the popular SPM brain imaging software. SPM is poorly documented (in fact, there is no official manual). Currently, users pose and answer support questions on an email list. A lot of knowledge about SPM is therefore located in the list archives, which suffer from a lack of structure (the same problem described in [14]). We hope to provide a wiki forum for users to ask and answer SPM (or other brain imaging) questions.
We predict that a wiki web site will provide more structure and will be easier to locate information with as compared to the email list archive.
[1] Bo Leuf, Ward Cunningham. The Wiki Way: Collaboration and Sharing on the Internet. Boston: Addison-Wesley, 2001.
[2] AndStuffWiki at http://andstuff.org/
[3] WikiPedia at http://www.wikipedia.org/
[4] The pattern collection of Portland Pattern Repository, at http://c2.com/cgi/wiki?CategoryPattern .
[5] The conflict resolution technique collection on MeatballWiki, at http://www.usemod.com/cgi-bin/mb.pl?ConflictResolution .
[6] It is informal general knowledge that wikis are being used more and more as an organizational tool for open source projects.
[7] Amy Cortese. "New Economy; Businesses are starting to toy with the wiki, an off-beat technology for fostering Web interaction". New York Times 19 May 2003, Late. ed. - final : C3+. Also available at http://www.socialtext.com/weblog/030519wikinyt.html.
[8] In fact, this report was written on a private wiki.
[9] Meatball Wiki. "Why Wiki Works", in Meatball Wiki. At http://www.usemod.com/cgi-bin/mb.pl?WhyWikiWorks, accessed Feb 11, 2002.
[10] Meatball Wiki. "Soft Security", in Meatball Wiki. At http://www.usemod.com/cgi-bin/mb.pl?SoftSecurity, accessed Feb 20, 2002.
[11] Meatball Wiki. "Community Solution", in Meatball Wiki. At http://www.usemod.com/cgi-bin/mb.pl?CommunitySolution, accessed Jul 2, 2001.
[12] Meatball Wiki. "View Point", in Meatball Wiki. At http://www.usemod.com/cgi-bin/mb.pl?ViewPoint, accessed Aug 22, 2001.
[13] "Certain topics tend to come up repeatedly on a discussion group. People subscribe and unsubscribe so there is always someone who does not realize that the topic was discussed to death six months ago."
David L. Carlson. "Electronic communications and communities" in Antiquity, vol. 71, number 274 (Dec. 1997), pp. 1049-51. York: Antiquity Trust. Available at http://intarch.ac.uk/antiquity/electronics/carlson.html.
[14] "A mailing list is great because it gets together people who have questions with people who have answers.
A mailing list archive is even better, because it lets thoughtful people with Frequently Asked Questions search for an immediate answer, and avoid bothering the people who have answers. Unfortunately, the answers in a mailing list archive become stale over time, are disorganized, and are hard to sift from the conversational noise of the mailing list."
Jon Howell. "Faq-O-Matic User's Guide", version 2.712. At http://faqomatic.sourceforge.net/fom-serve/cache/427.html, accessed Dec 8, 2001.
[15] Nancy Cohen and Peter Thoeny. "Mr. Twiki's Collaboration Software" in Open Magazine, volume 36 (Aug 2002). Newton, MA: CCI Communications. Available at http://www.open-mag.com/features/Vol_36/twiki/twiki.htm.
[16] There are journals which serve this function, but there are also websites, such as MIT's CogNet. The content and style of the CogNet articles is close to what NeuroWiki would ultimately like to achieve. However, it is expected that after a critical mass is reached, NeuroWiki will become more useful than CogNet for the reasons discussed.
[17] "If you don't like the perspective of the article you are perusing, you can go in and rephrase the concluding paragraph. If you stumble across a spelling mistake, you can fix it with a few quick keystrokes."
Steven Johnson. "THE YEAR IN IDEAS: A TO Z.; Populist Editing". New York Times 9 Dec. 2001, Late ed. - final : section 6, page 90. Also available at http://www.nytimes.com/2001/12/09/magazine/09POPULIST.html.
[18] Meatball Wiki. "Seed posting", in Meatball Wiki. At http://www.usemod.com/cgi-bin/mb.pl?SeedPosting, accessed May 26, 2003.
[19] Note that number of web pages on the site is much greater than that, indicating that, on average, a page on one of the web sites is currently much shorter than a typewritten page, which is true; a large number of the pages are currently very short, noting only a few facts (although an eventual goal is to fill out all of these pages to full size).
Also, note that "words" includes not only academic content but also meta-content such as navigational instructions and hyperlinks. Finally, as noted in the Method of Counting Text appendix, the word count includes words inside quotations marks as well as my own original words. These remarks apply equally to the "typewritten page" count.
[20] This figure was arrived at by adding the 21 UnderstandingIntelligence pages to the 4 FireInTheSky pages to the 10 other pages which have GL7's signature to the 9 other pages which have DavidAndel's signature, and also the pages AlphaBetaPruning, ElGordo, GwindleThrip, GwindleThrop, AiSingularity, TheAiSingularity, and then adding 10 to account for pages that I forgot about. Also, the "240 web pages" figure was arrived at by taking the total number of pages in AIWiki's index, subtracting 60, and rounding down.
[21] Even though it is possible for there to be other applications in the category of Community Programmable Wikis, I have named the one I wrote simply CPW.]
[22] Meatball Wiki. "Devolve Power", in Meatball Wiki. At http://www.usemod.com/cgi-bin/mb.pl?DevolvePower, accessed May 26, 2003.
[23] Meatball Wiki. "GodKing", in Meatball Wiki. At http://www.usemod.com/cgi-bin/mb.pl?GodKing, accessed May 26, 2003.
[24] Meatball Wiki. "Public Script", in Meatball Wiki. At http://www.usemod.com/cgi-bin/mb.pl?PublicScript, accessed May 26, 2003.
[25] The Cathedral and the Bazaar by Eric Raymond is a much-cited essay which advances the thesis that the greater decentralization associated with today's open source software development is more efficient than earlier hierarchial models of collaboration. The essay is published in First Monday;
Eric Raymond, 1998. "The Cathedral and the Bazaar", in First Monday, volume 3, number 3 (March). At http://www.firstmonday.dk/issues/issue3_3/raymond/, accessed November 17, 2001.
[26] See "Unit Testing" under the heading "Future Work" in the C.P.W. section for a solution to ameliorate this particular problem. Peer review should help a lot, too.
[27] There was a project called "Luke's Programmable Wiki", but my impression is that while users could write new code, they could not modify the wiki code. I am not sure, however. This project is no longer available.
[28] Meatball Wiki. "Peer Review", in Meatball Wiki. At http://www.usemod.com/cgi-bin/mb.pl?PeerReview, accessed March 27, 2002.
[29] Portland Pattern Repository. "Code Review", in Portland Pattern Repository. At http://c2.com/cgi/wiki?CodeReview, accessed June 25, 2002.
[30] Williams, Laurie, Kessler, Robert R., Cunningham, Ward, and Jeffries, Ron. "Strengthening the Case for Pair-Programming", in IEEE Software. July/Aug, 2000.
[31] Portland Pattern Repository. "Pair Programming", in Portland Pattern Repository. At http://c2.com/cgi/wiki?PairProgramming, accessed May 26, 2003.
[32] Branching means to take a software project and to split it into multiple copies, with each copy able to evolve differently. Merging means taking two or more somewhat different copies of the same project and unifying them. These operations are often used as a way of compartmentalizing software development so that different groups of developers can work for awhile without interfering with each other.
[33] Donald Knuth coined the term "literate programming", and defined it this way:
"I believe that the time is ripe for significantly better documentation of programs, and that we can best achieve this by considering programs to be works of literature. Hence, my title: "Literate Programming."
Let us change our traditional attitude to the construction of programs: Instead of imagining that our main task is to instruct a computer what to do, let us concentrate rather on explaining to human beings what we want a computer to do."
Donald Knuth. "Literate Programming (1984)", in Literate Programming. CSLI, 1992, pg. 99.
[34] Rohit Khare and Adam Rifkin, 1998. "Trust Management on the World Wide Web,", in First Monday, volume 3, number 6 (June). At http://www.firstmonday.dk/issues/issue3_6/khare/, accessed February 7, 2002.
CategoryALife CategoryAboutNeuroWiki CategoryAnatomical CategoryArchitecture CategoryArticles CategoryBehavior CategoryBioEngineering CategoryCannabinoid CategoryCategory CategoryCerebellum CategoryCog CategoryComplexity CategoryComputational CategoryConference CategoryConsciousness CategoryDimensionalityReduction CategoryDrug CategoryExperimentation CategoryFunding CategoryHomepage CategoryIo CategoryJobs CategoryJournal CategoryLab CategoryLearning CategoryLimbic CategoryMemory CategoryModeling CategoryNetwork CategoryNeuralCode CategoryNeuromorphic CategoryNeurotransmission CategoryNews CategoryOscillation CategoryPathology CategoryPersonality CategoryPhilosophy CategoryPhysiology CategoryProsthetic CategoryReference CategoryRepresentation CategoryResearchInstitute CategoryResource CategoryReticular CategorySimilarity CategorySimulation CategorySociety CategoryStimulant CategoryStudent CategorySummerProgram CategoryTodo
CategoryAboutAIWiki CategoryAgent CategoryCategory CategoryCompany CategoryConference CategoryConsultingCompany CategoryControlTask CategoryDimensionalityReduction CategoryFuturism CategoryGame CategoryGamePlayingTask CategoryHomePage CategoryJournal CategoryLargeAIDatabase CategoryLazyLearning CategoryLearning CategoryMetric CategoryMultiAgent CategoryNLP CategoryNeuralNet CategoryOntology CategoryOptimization CategoryPatternRecognitionTask CategoryPhilosophy CategoryProbability CategoryProgress CategoryReasoning CategoryReinforcementLearning CategoryReinforcementLearningTask CategoryRepresentation CategoryResearchInstitute CategoryResource CategoryRobotics CategorySearch CategorySimilarity CategorySociety CategorySupervisedLearning CategorySupervisedLearningTask CategorySymbolManipulationTask CategoryTask CategoryTimeSeries CategoryTodo CategoryUniversity
First, I downloaded every page on the wiki (using the index; that is, I used the program wget to get all links from that page, then take out the administrative links)
I took out all HTML with the command
perl -pi -e 's/<.*?>//g;' *
I took out the navigation bars at the top and bottom of each page, and the action bar at the bottom, and the title of the page. For example,
perl -pi -e '$bar = quotemeta("|"); s/NeuroWiki $bar RecentChanges $bar Index.*//;' *
perl -pi -e '$bar = quotemeta("|"); s/Edit text of this page $bar View.*//;' *
perl -pi -e 's/Neuroscience Wiki:.*//;' *
The amount of words was then counted with the 'wc' command
Note that both of these wikis are a collaborative effort and that other people were involved in writing some of the content. At this early stage, however, the vast majority was written by me. The numbers I gave are what I think can be attributed to my own personal contribution. However, the numbers do still include explicit quotations from outside sources.
[print out and append the following web pages:
]
[print out and append the following web pages:
]
